
本記事には広告(PR)が含まれています。
「dbtとは?」
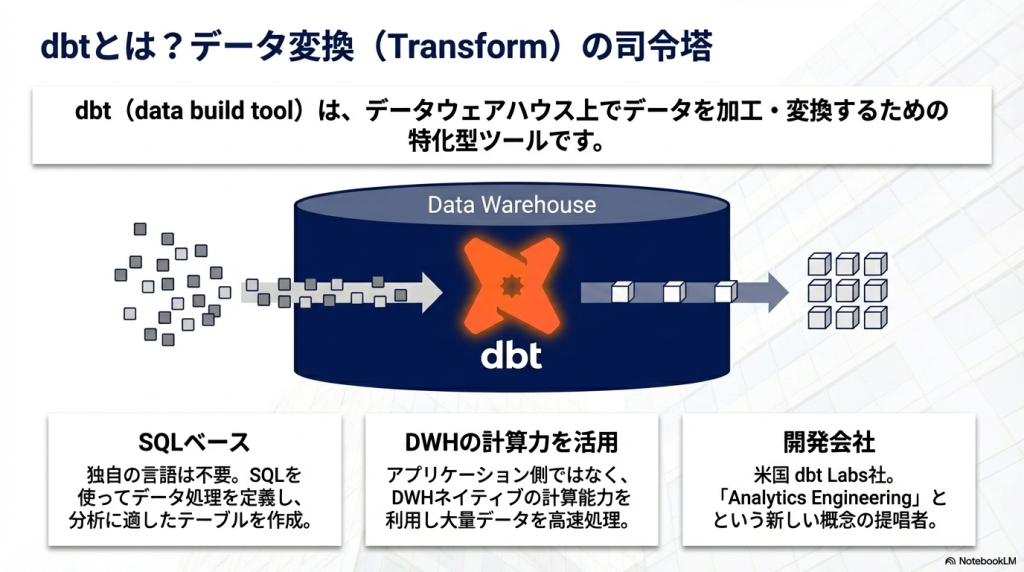
dbt(data build tool)は、データウェアハウス上でデータを加工・変換するためのツールです。SQLを使ってデータ処理を定義し、分析に適したテーブルやデータマートを作成できます。
近年は、SnowflakeやBigQueryなどのクラウドデータウェアハウスの普及により、企業が扱うデータ量が大きく増えています。そのため、データを整理し、分析しやすい形に変換する「データ基盤」の重要性が高まっています。
dbtは、このデータ変換(Transform)をSQLで管理できるツールです。データパイプラインをコードとして管理できるため、データエンジニアだけでなく、アナリストやアナリティクスエンジニアでも扱いやすいのが特徴です。
この記事では、dbtの基本的な仕組みや役割、使い方について初心者向けにわかりやすく解説します。
- dbt(data build tool)の概要と、なぜデータ基盤で注目されているのか
- ELTアーキテクチャにおけるdbtの役割と、ETLツールとの違い
- dbtの基本構造(models/tests/seeds/snapshots/macros)と仕組み
- インストールから
dbt runまでの使い方の流れとおすすめツールの組み合わせ - dbt Core / dbt Cloudの違い・選び方と導入のメリット/デメリット

dbtとは?
dbt(data build tool)は、データウェアハウス上でデータを加工・変換するためのツールです。SQLを使ってデータ処理を定義し、分析に適したテーブルやデータマートを作成できます。
近年、企業では大量のデータを活用した意思決定が重要になっています。しかし、生データのままでは分析が難しいため、データを整理し、分析しやすい形へ変換する工程が必要です。dbtはこの工程を効率化するツールとして注目されています。
従来はETLツールやPythonを使ってデータ変換を行うことが一般的でしたが、dbtではSQLを中心にデータパイプラインを構築できます。そのため、データエンジニアだけでなく、データアナリストやアナリティクスエンジニアも扱いやすいツールとして普及しています。
- データウェアハウス上のTransform(変換)に特化したOSSツール
- SQL中心なのでアナリストやアナリティクスエンジニアでも扱いやすい
- Snowflake/BigQueryなど主要DWHと組み合わせてモダンデータスタックの中核になる
dbtの概要
※data build tool
dbtとは「data build tool」の略で、データウェアハウスに保存されたデータを変換するためのツールです。主にSQLを使ってデータ処理を定義し、分析用のテーブルを作成します。
dbtの定義
dbtは、データウェアハウス上でデータ変換処理を管理するためのツールです。SQLをコードとして管理し、データパイプラインを構築できるのが特徴です。
SQLでデータ変換を行うツール
dbtではSQLを使ってデータ処理を定義します。例えば、売上データを月別に集計したり、顧客データを整理してマーケティング分析用のテーブルを作成したりすることができます。
SQLだけでデータ加工処理を管理できるため、データ分析チーム全体でデータ基盤を開発しやすくなります。
データウェアハウス上で動作する
dbtはデータウェアハウス上で動作するツールです。データをアプリケーション側で処理するのではなく、SnowflakeやBigQueryなどのDWHの計算能力を利用してデータ変換を実行します。
そのため、大量データでも高速に処理できるというメリットがあります。
dbtが登場した背景
dbtが注目されるようになった背景には、データ基盤のアーキテクチャの変化があります。特にクラウドデータウェアハウスの普及によって、データ処理の方法が大きく変わりました。
データ量の増加
企業が扱うデータ量は年々増加しています。ECサイト、アプリ、IoT、ログデータなど、さまざまなデータが日々生成されています。
これらのデータを分析するためには、効率的にデータを整理・加工する仕組みが必要になります。
DWHの普及
近年ではクラウド型データウェアハウスが普及しています。代表的なものとしては以下があります。
- Snowflake
- BigQuery
- Redshift
これらのDWHは大量データを高速に処理できるため、データ分析基盤として多くの企業で利用されています。
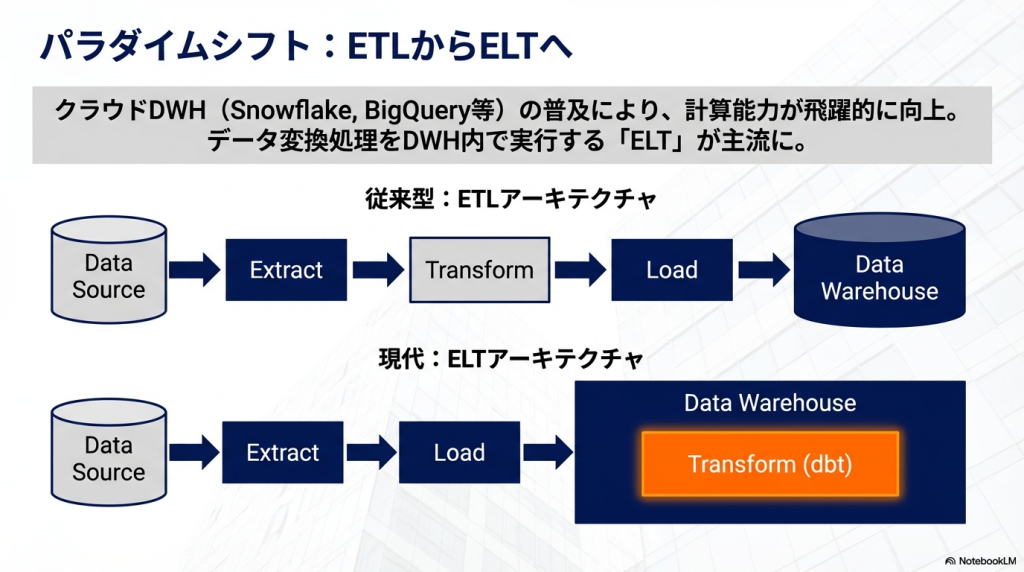
ELTアーキテクチャの台頭
従来はETL(Extract・Transform・Load)というデータ処理方式が主流でした。しかし現在はELT(Extract・Load・Transform)が一般的になっています。
ELTでは、まずデータをデータウェアハウスに保存し、その後SQLで加工します。このTransform部分を効率的に管理するために登場したツールがdbtです。
dbtを開発した会社
dbtはアメリカの企業である dbt Labs によって開発されました。
dbt Labs
dbt Labsはデータ基盤ツールを開発する企業で、世界中のデータチームに向けてdbtを提供しています。dbtはオープンソースとして公開されており、多くの企業で利用されています。
アメリカのデータ基盤企業
dbt Labsはデータ基盤分野に特化した企業であり、データ分析のワークフローを改善するためのツールを提供しています。
analytics engineeringの提唱
dbt Labsは「Analytics Engineering(アナリティクスエンジニアリング)」という概念を提唱しました。
これは、ソフトウェアエンジニアリングの考え方をデータ分析に取り入れるというものです。dbtはその実践ツールとして広く使われています。
dbtの役割
dbtは単体で使うツールではなく、データ基盤の一部として使われます。データ基盤では、データ収集から分析まで複数の工程があります。
dbtはその中で、データを分析用に変換する役割を担います。
データ基盤の基本構成
一般的なデータ基盤は、次のような構成で成り立っています。
- データソース
- データ連携(ETL/ELT)
- データウェアハウス
- データ変換
- BIツール
例えば、アプリケーションや業務システムからデータを取得し、それをデータウェアハウスに保存します。その後、dbtを使ってデータを整理し、BIツールで分析します。
このようにdbtは、データ分析を支える重要な役割を担っています。
dbtはTransformを担当するツール
データパイプラインは通常、次の3つの工程で構成されます。
Extract
Load
Transform
Extractはデータ取得、Loadはデータ保存、Transformはデータ加工を意味します。
dbtはこの中の Transform(データ変換) を担当するツールです。SQLを使ってデータを整理し、分析しやすいテーブルを作成します。
dbtとETLツールの違い
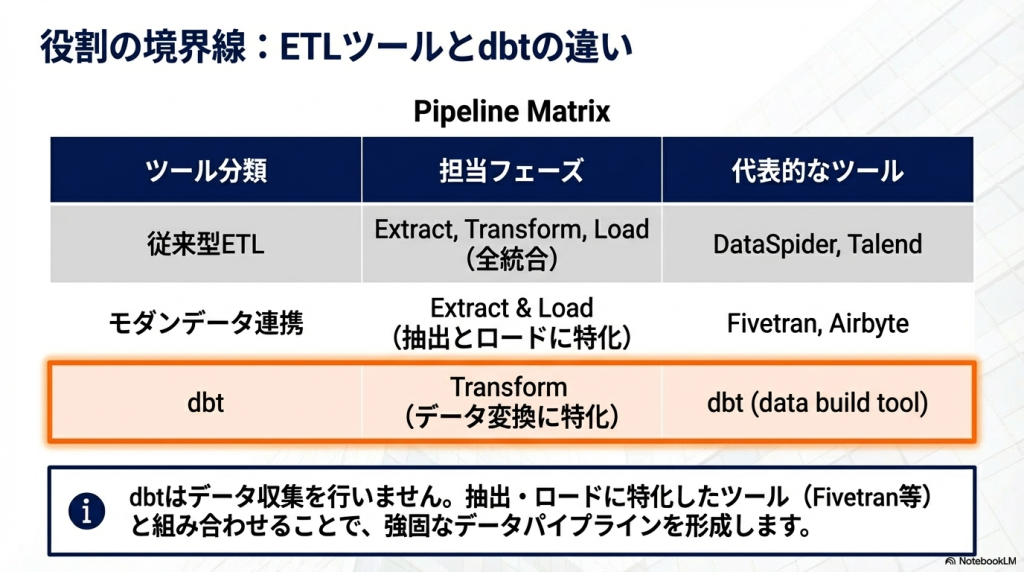
dbtはETLツールと比較されることが多いですが、役割は異なります。
ETLツールはデータ取得から変換までを行うツールですが、dbtはデータ変換に特化したツールです。
比較対象としてよく挙げられるツールには以下があります。
- DataSpider
- Fivetran
- Airbyte
- Talend
これらのツールは主にデータ連携を担当し、dbtはデータ変換を担当するという役割分担になります。
dbtはTransform(変換)専門のツール。データ取り込み(Extract/Load)はFivetran/Airbyte/DataSpiderなどのELT・ETLツールが担当し、dbtはDWH内部のSQLによる加工を担う、という役割分担で考えるとスッキリ整理できる。
dbtの仕組み
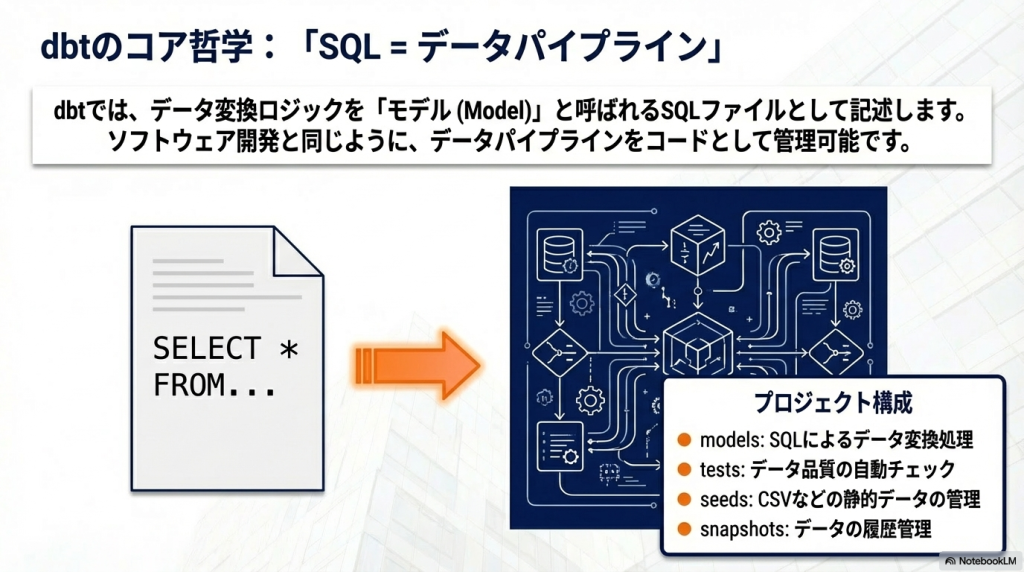
dbtは単なるSQL実行ツールではなく、データパイプラインをコードとして管理する仕組みを持っています。これにより、データ基盤開発をソフトウェア開発と同じように管理できます。
dbtの基本構造
dbtプロジェクトは複数の機能で構成されています。
- models
- tests
- seeds
- snapshots
- macros
これらを組み合わせることで、データ変換処理だけでなく、データ品質チェックや履歴管理なども行えます。
dbtのモデル(Model)
dbtの中心機能が「モデル」です。モデルとはSQLファイルで定義されたデータ変換処理のことです。
モデルでは次のような処理を定義できます。
- SQLファイル
- テーブル作成
- ビュー作成
つまり、dbtではSQLを組み合わせてデータパイプラインを構築します。
SQL = データパイプライン
という考え方になります。
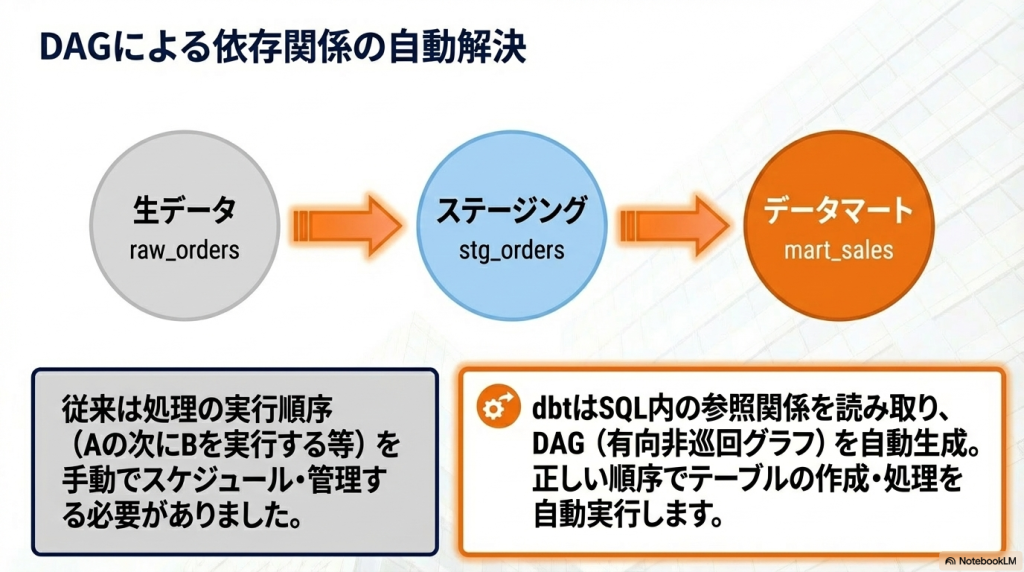
dbtの依存関係(DAG)
dbtではテーブル同士の依存関係を自動管理できます。この仕組みはDAG(Directed Acyclic Graph)と呼ばれます。
例えば次のような構造です。
raw_orders
↓
stg_orders
↓
mart_sales
まず生データを保存し、その後にステージングテーブルを作り、最終的に分析用のデータマートを作成します。dbtはこの順序を自動的に管理してくれます。
dbtの使い方

ここでは、実際に dbtをどのように使うのか を解説します。
dbtはSQLを中心にデータ変換パイプラインを作るツールなので、基本的な流れを理解すると仕組みが非常にシンプルに見えてきます。
dbtのインストール
dbtには大きく分けて2つの利用方法があります。
dbt Core
・オープンソース版
・ローカル環境で動作
・CLI(コマンドライン)で操作
・Git管理と相性が良い
エンジニアが最初に触るのは dbt Core が一般的です。
Python環境を用意し、pipでインストールします。
pip install dbt-core
その後、利用するDWHに合わせてアダプターをインストールします。
例:
pip install dbt-snowflake
pip install dbt-bigquery
dbt Cloud
・SaaS型サービス
・ブラウザから利用可能
・ジョブ実行やスケジューリングが可能
・GUIで管理できる
チーム開発や企業導入では dbt Cloud が使われることも多いです。
dbtプロジェクト作成
dbtでは、データ変換のロジックを プロジェクト単位 で管理します。
プロジェクトを作成するコマンドは以下です。
dbt init
このコマンドを実行すると、以下のようなディレクトリ構造が作られます。
dbt_project/
├ models
├ tests
├ macros
├ seeds
├ snapshots
└ dbt_project.yml
特に重要なのは modelsディレクトリ です。
ここに SQLファイルを書くだけでデータ変換処理を定義できます。
例えば
models/stg_orders.sql
のようなファイルを作成し、SQLを書きます。
select
order_id,
customer_id,
order_date
from raw.orders
このSQLが データパイプラインの処理になります。
dbtモデルの実行
作成したモデルは以下のコマンドで実行できます。
dbt run
このコマンドを実行すると、dbtは以下を自動で行います。
・SQLを解析
・依存関係を解決
・正しい順序でテーブルを作成
・DWH上で処理を実行
例えば
raw_orders
↓
stg_orders
↓
mart_sales
のような依存関係がある場合、dbtは**DAG(有向非巡回グラフ)**をもとに処理順を自動で決定します。
つまり
手動でパイプライン管理する必要がありません。
これがdbtの大きな強みです。
ここまでの流れを5つのSTEPで整理すると、dbtの全体像がつかみやすくなります。
Python環境を用意し、pip install dbt-coreでCoreをインストール。次に利用するDWHのアダプター(dbt-snowflake/dbt-bigqueryなど)を入れる。
dbt initでmodels/tests/macros/seeds/snapshotsを含むプロジェクトを生成。dbt_project.ymlで接続先や設定を定義する。
models/配下にSQLファイルを作成。SELECT文を書くだけで、テーブルやビューとしてDWHに具現化される。
dbt runでSQLを解析し、DAG(依存関係)に沿って正しい順序でテーブルを自動生成。手動でのパイプライン管理は不要。
dbt testでデータ品質を検証し、dbt docs generateでリネージュ付きのドキュメントを自動生成できる。

dbt の強さは「dbt run 一発で、依存関係に沿った正しい順番でテーブルを作ってくれる」ところ。手動のパイプライン管理から解放されるイメージで覚えておけばOKです。
dbtとよく組み合わせるツール
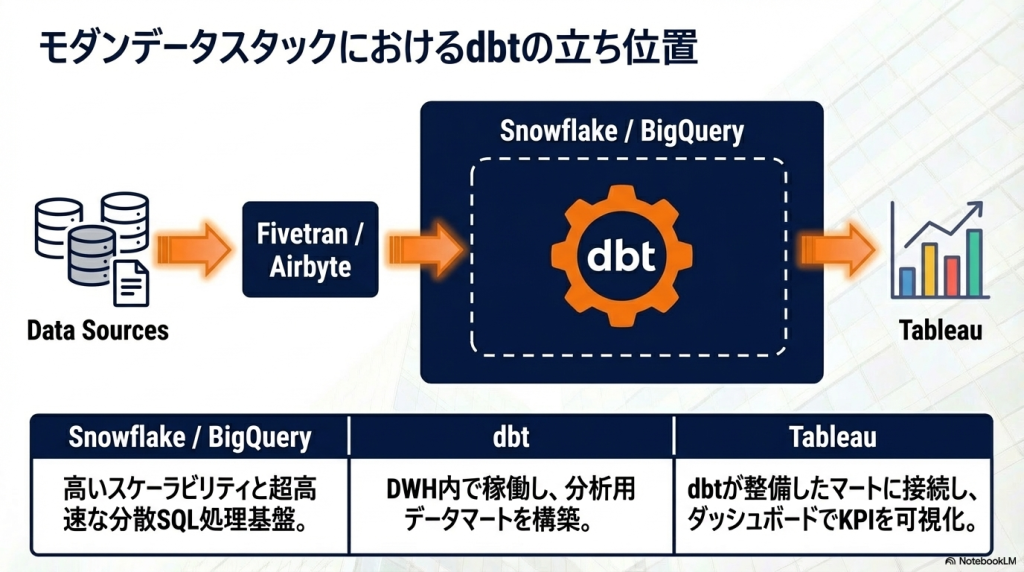
dbtは単体で使うというより、データ基盤の一部として利用されるツールです。
そのため、他のデータツールと組み合わせて使われるケースがほとんどです。
ここでは、実務でよく組み合わせるツールを紹介します。
Snowflake
Snowflake はクラウド型のデータウェアハウスです。
特徴
・高いスケーラビリティ
・分離されたストレージとコンピュート
・高速なSQL処理
dbtは Snowflake上でSQLを実行する形で動作します。
そのため、
Snowflake + dbt
の組み合わせは、モダンデータスタックの代表構成になっています。
BigQuery
Google BigQuery はGoogle Cloudが提供するDWHです。
特徴
・サーバーレス
・超高速な分散SQL
・大規模データ分析に強い
BigQueryもdbtとの相性が非常に良く、
BigQuery
↓
dbt
↓
BIツール
という構成は多くの企業で採用されています。
Tableau
Tableau はBIツールの代表格です。
BIツールの役割は
・ダッシュボード作成
・データ可視化
・KPI分析
です。
dbtで作成した データマート をTableauに接続することで、分析用のダッシュボードを構築できます。
つまり
dbt = 分析用データの準備
Tableau = データの可視化
という役割分担になります。
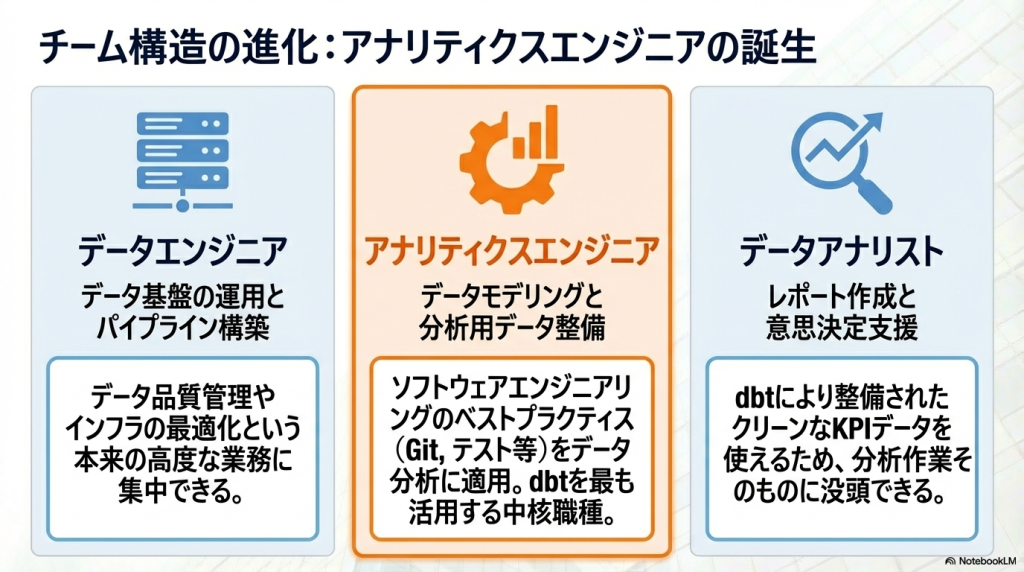
dbtを使う職種
dbtは単なるツールではなく、データ組織の働き方を変えるツールとも言われています。
そのため、複数の職種が関わります。
データエンジニア
データエンジニアは
・データパイプライン構築
・データ基盤運用
・DWH設計
などを担当します。
dbtを使うことで
・データ変換ロジック
・データマート構築
・データ品質管理
を効率的に実装できます。
アナリティクスエンジニア
アナリティクスエンジニアはdbtと最も相性の良い職種です。
役割
・データモデリング
・KPI設計
・分析用データ整備
従来は
データエンジニア
↓
アナリスト
という分業でしたが、dbtの登場により
分析者自身がデータモデルを作れる
ようになりました。
この役割を体系化したのが Analytics Engineering です。
データアナリスト
データアナリストは
・データ分析
・レポート作成
・意思決定支援
を行う職種です。
dbtを使うことで
・分析用テーブル
・KPIデータ
・集計テーブル
が整備されるため、分析作業に集中できる環境が整います。
dbt Coreとdbt Cloudの違い
dbtには大きく分けてdbt Coreとdbt Cloudの2つの提供形態があります。導入を検討する際には、それぞれの違いを理解しておくことが大切です。
dbt Core(OSS版)
dbt Coreはオープンソースで提供されているコマンドラインツールです。無料で利用でき、自社でPython環境やGitリポジトリを用意して運用します。CI/CDや実行スケジューラーは、Airflowなど別のツールと組み合わせて構築する必要があります。
小規模チームや、すでにデータエンジニアリングの基盤がある企業に向いています。
dbt Cloud(SaaS版)
dbt CloudはdbtをマネージドSaaSとして提供するサービスです。Webブラウザ上のIDE、ジョブスケジューラー、Git連携、ドキュメントホスティングなどが標準で組み込まれています。
インフラ構築の手間を省きたいチームや、データアナリストを中心に運用したいチームに向いています。
どちらを選ぶべきか
- コストを抑えたい・既存の基盤と統合したい → dbt Core
- 導入スピードと運用負荷の低さを重視したい → dbt Cloud
- まずは個人で学習したい → dbt Core(ローカル環境)
dbtのテスト機能(dbt test)
dbtの大きな特徴の1つが、データ品質を継続的に検証できるテスト機能です。SQLの結果に対して自動でテストを実行することで、データの異常を早期に検知できます。
スキーマテスト
YAMLファイルでテストを定義することで、特定のカラムに対するチェックを宣言的に行えます。よく使われる組み込みテストには次のようなものがあります。
- not_null:NULLが含まれていないかを検証
- unique:値が一意であることを検証
- accepted_values:許可された値だけが含まれているかを検証
- relationships:他テーブルとの参照整合性を検証
カスタムデータテスト
組み込みテストだけでなく、SQLで独自のテストを書くこともできます。例えば「売上が負の値になっていないか」「注文日が未来日付になっていないか」など、業務ルールに基づくチェックを実装できます。
テストを運用に組み込むメリット
CI/CDパイプラインでdbt testを実行することで、データの異常がダッシュボードに反映される前に検知できます。これにより、誤ったデータに基づく意思決定を未然に防ぐことができます。
dbtのドキュメント機能(dbt docs)
dbtには、データパイプラインのドキュメントを自動生成する機能があります。SQLとYAMLに記述した内容をもとに、テーブル間の依存関係や各カラムの説明をWebページとして公開できます。
生成されるドキュメントの内容
- モデル一覧と説明
- カラムごとのdescriptionとデータ型
- モデル間のリネージュ(依存関係グラフ)
- ソースデータとの関係
リネージュグラフでデータの流れを可視化
リネージュグラフを使うと、「ある分析テーブルがどのソースに由来しているか」「あるカラムを変更すると、どのレポートに影響するか」を直感的に把握できます。これはデータガバナンスや影響範囲の特定に非常に役立ちます。
チームコミュニケーションへの効果
ドキュメントが自動生成されることで、データアナリストとビジネスサイドの認識ズレを減らせます。「このKPIはどのテーブルから計算されているのか」といった質問に、リネージュを見せながら答えられるようになります。
Materializationの種類と使い分け
dbtでは、モデルをどのような形でデータウェアハウスに具現化するかをMaterialization(マテリアライゼーション)として指定できます。適切に使い分けることで、コストとパフォーマンスを両立できます。
table
実行のたびにテーブルとして再作成する方式です。シンプルでわかりやすい反面、データ量が多いと実行コストが大きくなります。中間集計や日次更新の分析テーブルに向いています。
view
SQLをビューとして登録する方式です。実体データを持たないため保存コストはかかりませんが、参照されるたびにクエリが実行されるため、軽量な変換や頻繁に参照されないモデルに向いています。
incremental
差分のみを追加・更新する方式です。日次のログデータなど大量データを扱うケースで有効で、フルリビルドに比べて大幅にコストを削減できます。一方で、設計を誤るとデータの欠損や重複が発生するため注意が必要です。
ephemeral
物理的なオブジェクトを作らず、CTE(共通テーブル式)として他モデル内に展開される方式です。中間処理を分割しつつ、不要なテーブル生成を避けたい場合に役立ちます。
Jinja・マクロ・変数による拡張
dbtのSQLは、テンプレートエンジンのJinjaを組み合わせて記述できます。これにより、SQLでありながら制御構文や関数のような仕組みを使えるのが大きな特徴です。
Jinjaによるテンプレート化
Jinjaを使うと、SQLの中に変数や条件分岐を埋め込めます。例えば、開発環境と本番環境で参照するスキーマを切り替えるといった処理が、設定ファイルベースで実現できます。
マクロによる再利用
共通処理をマクロとして切り出すことで、複数モデルから同じロジックを呼び出せます。日付の整形や、共通の集計ロジックなどをマクロ化することで、SQLの重複を減らし、保守性を高められます。
変数(vars)の活用
プロジェクト全体で使う設定値をvarsとして宣言できます。例えば「分析対象期間」や「店舗ID」などをvarsとして外出ししておくと、実行時に値を切り替えながら柔軟にパイプラインを動かせます。
dbt導入のメリット・デメリット
dbtは強力なツールですが、すべてのチームに最適というわけではありません。ここでは導入を検討する際に押さえておきたいメリットとデメリットを整理します。
メリット
- SQLだけでデータ変換パイプラインを構築できる
- バージョン管理(Git)と相性がよく、レビュー文化を作りやすい
- テストとドキュメント生成が標準で備わっている
- 依存関係(DAG)を自動管理してくれる
- アナリティクスエンジニアリングの実践に向いている
デメリット・注意点
- SQLとデータウェアハウスの基本知識が前提となる
- JinjaやYAMLの学習コストが発生する
- 小規模なデータ基盤ではオーバースペックになることがある
- dbt Cloudは利用人数によってコストが上がる
- Transform以外(取り込み・配信)は別ツールと組み合わせが必要
- SQLとDWHの基本知識が前提:完全なノーコードではない
- Jinja/YAMLの学習コスト:素のSQLよりは習熟が必要
- 小規模基盤ではオーバースペック:データ量・組織規模に応じて判断
導入が向いているチーム
「データアナリストが自らパイプラインを書きたい」「データ品質を継続的に担保したい」「複雑な依存関係を持つ分析テーブルを保守したい」といった課題を持つチームでは、dbt導入の効果が大きくなります。
コストとパフォーマンスの最適化
dbtを本格的に運用すると、データウェアハウスのコンピューティングコストがボトルネックになることがあります。ここでは、dbtプロジェクトを運用するうえで押さえておきたい最適化のポイントを紹介します。
incrementalモデルでの差分更新
日次・時間次で更新される大規模ファクトテーブルは、毎回フルリビルドするとコストが膨らみます。incrementalモデルを使い、新規・更新分だけを処理することで実行時間とコストを削減できます。
適切なクラスタリング・パーティション設計
Snowflakeのクラスタリングキーや、BigQueryのパーティション・クラスタリングを活用すると、スキャン量が削減されコストが下がります。dbtではconfigブロックでこれらを指定可能です。
実行スケジュールの最適化
すべてのモデルを同じ頻度で実行する必要はありません。ダッシュボードでの利用頻度に応じて実行間隔を分けることで、不要な処理を減らせます。dbtのtagやselectorを使うと、対象モデルを柔軟に絞り込めます。
dbtを学ぶためのリソース
これからdbtを学びたい方に向けて、無理なくステップアップしていけるリソースを紹介します。
公式ドキュメント
まず最初に参照したいのが、dbt Labsが提供する公式ドキュメントです。チュートリアルから設定リファレンスまで網羅されており、最新の情報を得るには公式が最も信頼できます。
dbt Learn(無料コース)
dbt Labsが提供する公式の学習プラットフォームには、無料のオンラインコースが用意されています。ハンズオン形式で進められるため、初学者が体系的に学ぶのに適しています。
実プロジェクトで触ってみる
チュートリアルを終えたら、小さくてもよいので実データで動かしてみるのが上達の近道です。BigQueryやSnowflakeのフリープランと組み合わせて、自分のローカル環境からdbt Coreを動かす構成は、学習用として始めやすい構成です。
コミュニティの活用
dbt CommunityのSlackや、各社のテックブログ、勉強会などで実運用の事例が多く共有されています。書籍だけでは得られない「現場でつまずいたポイント」を知るうえで非常に役立ちます。
dbtに関するよくある質問(FAQ)
Q. dbtはプログラミング初心者でも使えますか?
A. SQLが書ける方であれば、基本機能はすぐに使い始められます。ただし、Jinjaやマクロ、CI/CDとの統合といった応用的な部分では、ある程度のエンジニアリング知識が求められます。まずはシンプルなSQLモデルから始め、徐々にテストやマクロに範囲を広げていくのがおすすめです。
Q. dbtとAirflowはどう違いますか?
A. Airflowはワークフロー全体のスケジューリング・オーケストレーションを担うツールであり、dbtはデータ変換(Transform)に特化したツールです。「Airflowからdbtを呼び出す」という組み合わせで使うことが多く、両者は競合ではなく役割分担の関係にあります。
Q. dbtを導入すれば、データエンジニアは不要になりますか?
A. 不要にはなりません。dbtによってアナリストが変換ロジックを書きやすくはなりますが、データウェアハウス設計、データ取り込み、CI/CD、コスト管理など、データエンジニアの役割は依然として重要です。dbtはアナリストとエンジニアの協業を促進するツールと捉えるのが適切です。
Q. dbtはどのデータウェアハウスで使えますか?
A. Snowflake、BigQuery、Redshift、Databricks、PostgreSQLなど、主要なデータウェアハウス・データベースに対応しています。アダプターという仕組みで接続先を切り替えられるため、利用中のDWHに合わせて導入できます。
Q. dbtの導入はどのような流れで進めればよいですか?
A. 一般的には、(1)小さなプロジェクトでPoCを行う、(2)既存SQLをdbtモデルに移行する、(3)テストとドキュメントを整備する、(4)CI/CDに組み込む、という順序で進めると無理がありません。最初から全社展開を狙うよりも、1つの分析テーマに絞って効果検証するのが成功しやすいパターンです。
dbtまとめ
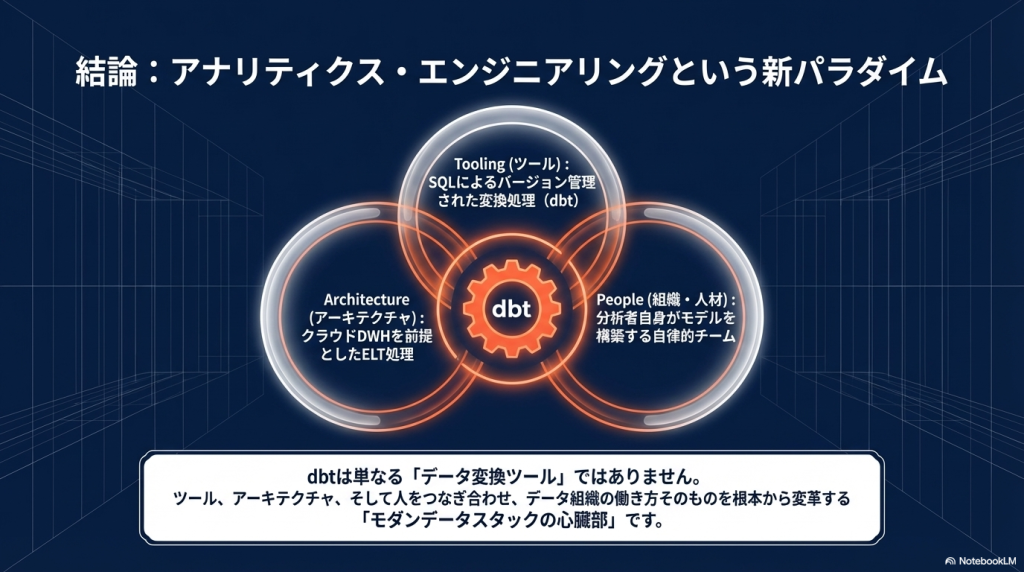
dbtは、SQLでデータ変換を行うデータ基盤ツールです。
📌 dbtのポイントまとめ
- データウェアハウス上で動作する
- SQLでデータパイプラインを構築できる
- データ品質テストが可能
- Gitによるバージョン管理ができる
- Analytics Engineeringを実現するツール
特に、クラウドDWHの普及により
ELTアーキテクチャ
が主流になったことで、dbtの重要性は急速に高まっています。
今後のデータエンジニアリングでは、
・Snowflake
・BigQuery
・dbt
・BIツール
を組み合わせた モダンデータスタック が標準的な構成になると考えられています。
 Winスクール | 【初心者向け】 ・20~30代におすすめ ・データ分析・AIに特化 公式サイトで無料登録する |
|---|




コメント